Our digital world and data are growing faster today than any time in the past—even faster than our computing power. Deep learning helps us quickly make sense of immense data, and offers users the best AI-powered products and experiences.
To continually improve user experience, our challenge, then, is to quickly improve our deep learning models for existing and emerging application domains. Model architecture search creates important new improvements, but this search often depends on epiphany; Breakthroughs often require complex reframing of the modeling problem, and can take weeks or months of testing.
It be great if we could supplement model architecture search with more reliable ways to improve model accuracy.
Today, we are releasing a large-scale study showing that deep learning accuracy improves predictably as we grow training data set size. Through empirical testing, we find predictable accuracy scaling as long as we have enough data and compute power to train large models. These results hold for a broad spectrum of state-of-the-art models over four application domains: machine translation, language modeling, image classification, and speech recognition.
More specifically, our results show that generalization error—the measure of how well a model can predict new samples—decreases as a power-law of the training data set size. Prior theoretical work also shows that error scaling should be a power-law. However, these works typically predict a “steep” learning curve—the power-law exponent is expected to be -0.5—suggesting models should learn very quickly. Our empirically-collected learning curves show smaller magnitude exponents in the range
[-0.35, -0.07]: Real models actually learn real-world data more slowly than suggested by theory.
As an example, consider our results for word language modeling below (Note the log-log scale!):![]()
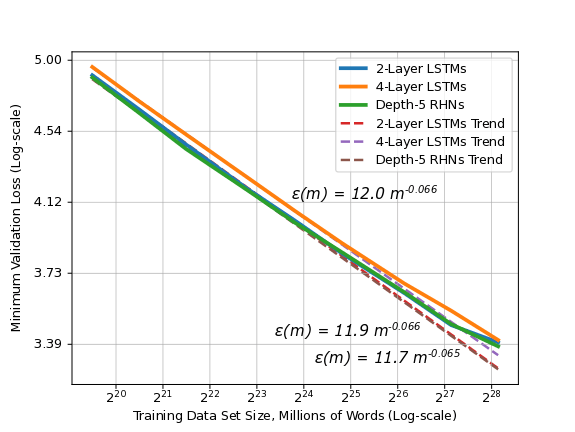
Word language models show predictable power-law validation error scaling as training set size grows.
For word language modeling, we test LSTM and RHN models on subsets of the Billion Word dataset. The figure above shows each model architecture’s validation error (an approximation to generalization error) for the best-fit model size at each training set size. These learning curves are each predictable power-laws, which surprisingly have the same power-law exponent. On larger training sets, models tend away from the curve, but we find that optimization hyperparameter search often closes the gap.
